Keras入门笔记(一)-从二分类问题到多分类问题、图像识别问题
Keras是一个Python深度学习框架,是个高层的API库。它不同于TensorFlow、PyTorch等微分器,Keras高度封装了底层的微分计算等操作,提供了用户友好的API,并且支持在TensorFlow、Theano和CNTK这三个底层微分库之间切换。目前,Keras已被钦定为TensorFlow的用户接口,其地位相当于TorchVision之于PyTorch
- 本文主要基于Keras2作介绍。
Keras的结构
Keras中我们
utilsactivations:提供了常见的激活函数,如relu等。applications:backend:提供了TensorFlow、Theano和CNTK的底层接口。datasets:提供了一些常用的小数据集,用于上手。enginelayers:提供了常见的网络结构层,是Keras最重要的包。preprocessing:数据预处理模块,也提供了数据增强的常用包。wrapperscallbacksconstraintsinitializers:提供了参数初始化的方法。metricsmodels:模型是Keras对网络层、优化器等结构的组织模块。losses:提供了常见的损失函数/目标函数,如Mean-Squared-Error等。optimizers: 优化器,包含了一些优化的方法。regularizers:提供了一系列正则器。
Keras的常见结构
① 模型
Keras的核心数据结构是“模型”,模型指的是对网络层的组织方式。目前,Keras的模型只有两种形式:
- Sequential
- Functional
xxxxxxxxxxfrom keras.models import Sequentialnetwork = Sequential()就构建了一个序列模型,接下下来就是不断往这个网络结构中添加不同的网络层并构建它们的连接次序。
② 网络层
网络层由keras.layers进行定义:
xxxxxxxxxxfrom keras.layers import Dense就引入了一个全连接层,接着我们无返回地把它添加到网络结构中:
xxxxxxxxxxnetwork.add(Dense(units=512, activation='relu', inputshap=(1024, )))network.add(Dense(units=10, activation='softmax'))就为网路结构添加了一个512个神经元的全链接层和10个神经元的输出层。
注意到:只有第一层需要指定输入数据的尺寸;此后的每一层将会自动进行推导。
③ 模型编译和训练
现在我们要指定模型的训练方式,我们需要重点关心的有:
optimizer:优化器,可能会影响到模型的收敛速度loss:模型的目标函数/损失函数metrics:指标列表,训练时将会根据该列表记录训练效果的衡量值epochs、batch_size:训练的轮次和梯度下降时每个batch将包含的样本数。verbose:控制台日志,值为0|1|2——分别对应”不在控制台输出任何消息“、“训练每轮训练进度”、“仅输出训练轮的信息”validation_data、validation_split:验证集或自动划分验证集的比例。
我们调用model.compile方法进行编译:
xxxxxxxxxxnetwork.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy'])随后,再对编译完毕的模型进行训练:
xxxxxxxxxxnetwork.fit(train_data, train_labels, epochs=10, batch_size=1024, validation_split=0.3, verbose=2)二分类问题:电影评论分类
二分类问题可能是应用最广泛的机器学习问题。我们可以利用Keras自带的IMDB数据集进行初步上手练习。
IMDB 数据集它包含来自互联网电影数据库(IMDB)的 50 000 条严重两极分化的评论。数据集被分为用于训练的 25 000 条评论与用于测试的 25 000 条评论,训练集和测试集都包含 50% 的正面评论和 50% 的负面评论。
imdb_data是由评论词组成的索引列表,其前三位为保留值,即真正的评论词索引从序数 开始。imdb_label是由0|1组成的二值化评价。
xxxxxxxxxxfrom keras.datasets import imdbfrom keras.layers import Densefrom keras.models import Sequentialimport numpy as npimport matplotlib.pyplot as pltdef ont_hot(data_mat, dim): """ 对一个矩阵进行独热编码 :param data_mat: 数据矩阵 :param dim: 独热编码的维度 :return: 返回独热编码后的数据矩阵 """ res = np.zeros((len(data_mat), dim)) for i, index in enumerate(data_mat): res[i][index] = 1.0 return res# 取前10000个高频评论词汇nb_words = 10000(train_data, train_labels), (test_data, test_labels) = imdb.load_data(num_words=nb_words)# 对训练数据、测试数据进行独热编码和numpy向量化train_data = ont_hot(train_data, nb_words)test_data = ont_hot(test_data, nb_words)train_labels = np.asarray(train_labels).astype('float32')test_labels = np.asarray(test_labels).astype('float32')network = Sequential()network.add(Dense(16, activation='relu', input_shape=(nb_words,)))network.add(Dense(16, activation='relu', input_shape=(16,)))network.add(Dense(1, activation='sigmoid'))network.compile(optimizer='adam', loss='binary_crossentropy', metrics=['accuracy'])history = network.fit(train_data, train_labels, epochs=10, batch_size=1024, validation_split=0.3, verbose=2).history# --模型的应用--# 随机选择一项进行预测result = list(map(lambda x: 1 if x > 0.5 else 0, network.predict(test_data)))print('positive' if result[np.random.randint(len(result))] == 1 else 'negative')# 画图,可以明显看到过拟合现象train_loss, val_loss = history['loss'], history['val_loss']epochs = range(len(train_loss))plt.plot(epochs, train_loss, 'bo', label='train loss')plt.plot(epochs, val_loss, 'b-', label='val loss')plt.xlabel('epochs')plt.ylabel('loss')plt.legend()plt.show()多分类问题:路透社新闻评论
透社数据集,它包含许多短新闻及其对应的主题,由路透社在 1986 年发布。它是一个简单的、广泛使用的文本分类数据集。
路透社新闻数据集和IMDB数据集类似,只不过其label为 维的输出值。
xxxxxxxxxxfrom keras.datasets import reutersfrom keras.utils import to_categoricalfrom keras.models import Sequentialfrom keras.layers import Denseimport numpy as npimport matplotlib.pyplot as pltnb_words = 10000(train_data, train_labels), (test_data, test_labels) = reuters.load_data(num_words=nb_words)def ont_hot(data_mat, dim): """ 对一个矩阵进行独热编码 :param data_mat: 数据矩阵 :param dim: 独热编码的维度 :return: 返回独热编码后的数据矩阵 """ res = np.zeros((len(data_mat), dim)) for i, index in enumerate(data_mat): res[i][index] = 1.0 return restrain_data = ont_hot(train_data, nb_words)test_data = ont_hot(test_data, nb_words)# 采用 loss='categorical_crossentropy'# train_labels = to_categorical(train_labels)# test_labels = to_categorical(test_labels)# 采用 loss='sparse_categorical_crossentropy' 只需要编译成一个numpy张量即可# train_labels = np.array(train_labels)# test_labels = np.array(test_labels)network = Sequential()network.add(Dense(128, activation='relu', input_shape=(nb_words,)))network.add(Dense(64, activation='relu'))network.add(Dense(46, activation='softmax')) # 与imdb数据集不同,其输出不是二分类问题network.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics=['accuracy'])history = network.fit(train_data, train_labels, epochs=20, batch_size=1024, validation_split=0.3, verbose=2).history# --模型的应用--# 画图,可以明显看到过拟合现象train_loss, val_loss = history['loss'], history['val_loss']epochs = range(len(train_loss))plt.plot(epochs, train_loss, 'bo', label='train loss')plt.plot(epochs, val_loss, 'b-', label='val loss')plt.xlabel('epochs')plt.ylabel('loss')plt.legend()plt.show()回归问题:波士顿房价
任何看过西瓜书或吴恩达视频课程的同学都不会对这个数据集感到陌生。
不同于上两个问题的做法,我们将在下文采用新的损失函数和评价指标。
首先我们将采用K折法对模型进行评价,所以我们需要多次编译模型,因此需要构建一个模块化的模型方法:nn()。
xxxxxxxxxxfrom keras.datasets import boston_housingfrom keras.models import Sequentialfrom keras.layers import Denseimport matplotlib.pyplot as pltimport numpy as npdef z_score(data, axis=0): """ :param data: 2-D numpy - array :param axis: ... :return: """ mean = data.mean(axis=axis) std = data.std(axis=axis) return (data - mean) / stddef nn(data_shape): """ :param data_shape: (size of samples, num of features) :return: """ k_model = Sequential() k_model.add(Dense(64, activation='relu', input_shape=(data_shape[1],))) k_model.add(Dense(32, activation='relu')) k_model.add(Dense(1)) # MSE 均方误差 # MAE 平均绝对误差 : 预测值与目标值之差的绝对值 k_model.compile(optimizer='sgd', loss='mse', metrics=['mae']) return k_model(train_data, train_targets), (test_data, test_targets) = boston_housing.load_data()# 标准化train_data = z_score(train_data)test_data = z_score(test_data)# K折法训练k = 4histories = []for i in range(k): network = nn(train_data.shape) k_nums_samples = train_data.shape[0] // k k_val_data = train_data[i * k_nums_samples:(i + 1) * k_nums_samples] k_val_targets = train_targets[i * k_nums_samples:(i + 1) * k_nums_samples] k_train_data = \ np.concatenate([train_data[: i * k_nums_samples], train_data[(i + 1) * k_nums_samples:]], axis=0) k_train_targets = \ np.concatenate([train_targets[: i * k_nums_samples], train_targets[(i + 1) * k_nums_samples:]], axis=0) history = network.fit(k_val_data, k_val_targets, epochs=200, batch_size=256, validation_data=(k_val_data, k_val_targets), verbose=2).history histories.append(history['val_loss'])# --模型的应用--# 画图,可以明显看到过拟合现象epochs = len(histories[0])avg_val_loss = [np.mean([k[i] for k in histories]) for i in range(epochs)]plt.plot(range(epochs), avg_val_loss, 'r-.', label='val loss')plt.xlabel('epochs')plt.ylabel('loss')plt.legend()plt.show()
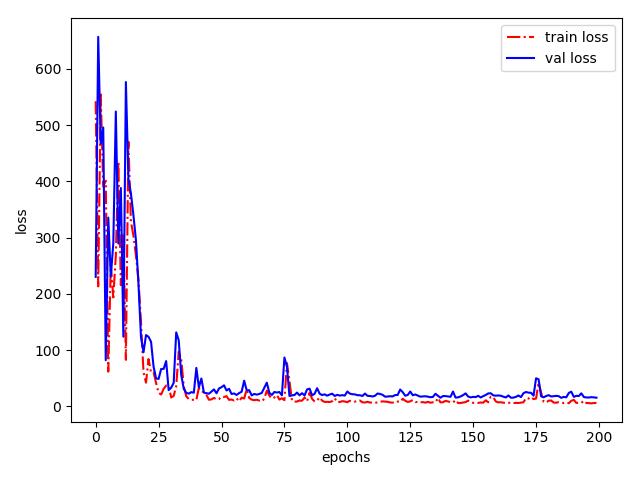
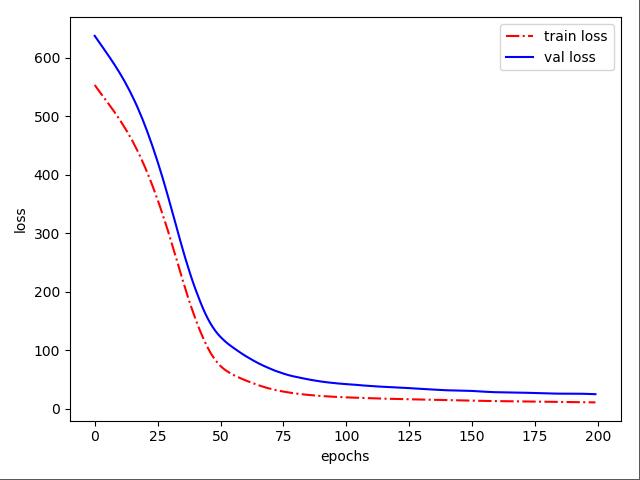
如果把上文中的优化器换成adam(滑动平均),会观察到一个更平缓的函数图像:
图像识别问题:MNIST数据集
MINIST数据集非常经典,不需要进行更多地介绍,采用全连接对MNIST进行训练也很简单:
xxxxxxxxxximport kerasfrom keras.datasets import mnistfrom keras.layers import Densefrom keras.models import Sequential# 载入数据集(train_images, train_labels), (test_images, test_labels) = mnist.load_data()x_train, h, w = train_images.shapetrain_images = train_images.reshape((x_train, h * w)) / 255 # 归一化处理,可以使得其更快收敛x_test, h, w = test_images.shapetest_images = test_images.reshape((x_test, h * w)) / 255# 对一个list进行one-hot编码train_labels = keras.utils.to_categorical(train_labels)test_labels = keras.utils.to_categorical(test_labels)# 构建网络模型network = Sequential()network.add(Dense(512, activation='relu', input_shape=(h * w,)))network.add(Dense(128, activation='relu', input_shape=(512,)))network.add(Dense(10, activation='softmax'))network.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy'])network.fit(train_images, train_labels, epochs=10, batch_size=1024, verbose=2)network.summary()print('loss, acc=', network.evaluate(test_images, test_labels))# --模型的应用--import matplotlib.pyplot as pltimport numpy as npindex = np.random.randint(0, x_test) # random pick a test-imageplt.imshow(test_images.reshape(x_test, h, w)[index], cmap=plt.cm.binary)plt.show()res = network.predict(test_images)[index]# 输出的是softmax()的值,其中最大值对应的索引即为预测的数字print('The digit is %d' % np.where(res == np.max(res))[0][0])不同的是,我们可以引入CNN来对图像进行处理,例如VGG-16模型:
x
from keras import modelsfrom keras import Sequentialfrom keras.layers import Dense, Activation, Conv2D, MaxPooling2D, Flatten, Dropoutfrom keras.layers import Inputfrom keras.optimizers import SGDimport cv2import numpy as npimport jsonfrom keras.datasets import mnist # 从keras中导入mnist数据集from keras import utils # 从keras中导入mnist数据集resize_to = 64 # 重塑尺寸(x_train, y_train), (x_test, y_test) = mnist.load_data() # 下载mnist数据集x_train = [cv2.cvtColor(cv2.resize(i, (resize_to, resize_to)), cv2.COLOR_GRAY2RGB) for i in x_train] # 变成彩色的x_test = [cv2.cvtColor(cv2.resize(i, (resize_to, resize_to)), cv2.COLOR_GRAY2RGB) for i in x_test] # 变成彩色的x_train = np.array(x_train).reshape(60000, resize_to, resize_to, 3)x_test = np.array(x_test).reshape(10000, resize_to, resize_to, 3)y_train, y_test = utils.to_categorical(y_train, 10), utils.to_categorical(y_test, 10) # 独热编码x_train, x_test = x_train / 255, x_test / 255 # 归一化处理model = Sequential()# BLOCK 1model.add(Conv2D(filters=64, kernel_size=(3, 3), activation='relu', padding='same', name='block1_conv1', input_shape=(resize_to, resize_to, 3)))model.add(Conv2D(filters=64, kernel_size=(3, 3), activation='relu', padding='same', name='block1_conv2'))model.add(MaxPooling2D(pool_size=(2, 2), strides=(2, 2), name='block1_pool'))# BLOCK2model.add(Conv2D(filters=128, kernel_size=(3, 3), activation='relu', padding='same', name='block2_conv1'))model.add(Conv2D(filters=128, kernel_size=(3, 3), activation='relu', padding='same', name='block2_conv2'))model.add(MaxPooling2D(pool_size=(2, 2), strides=(2, 2), name='block2_pool'))# BLOCK3model.add(Conv2D(filters=256, kernel_size=(3, 3), activation='relu', padding='same', name='block3_conv1'))model.add(Conv2D(filters=256, kernel_size=(3, 3), activation='relu', padding='same', name='block3_conv2'))model.add(Conv2D(filters=256, kernel_size=(3, 3), activation='relu', padding='same', name='block3_conv3'))model.add(MaxPooling2D(pool_size=(2, 2), strides=(2, 2), name='block3_pool'))# BLOCK4model.add(Conv2D(filters=512, kernel_size=(3, 3), activation='relu', padding='same', name='block4_conv1'))model.add(Conv2D(filters=512, kernel_size=(3, 3), activation='relu', padding='same', name='block4_conv2'))model.add(Conv2D(filters=512, kernel_size=(3, 3), activation='relu', padding='same', name='block4_conv3'))model.add(MaxPooling2D(pool_size=(2, 2), strides=(2, 2), name='block4_pool'))# BLOCK5model.add(Conv2D(filters=512, kernel_size=(3, 3), activation='relu', padding='same', name='block5_conv1'))model.add(Conv2D(filters=512, kernel_size=(3, 3), activation='relu', padding='same', name='block5_conv2'))model.add(Conv2D(filters=512, kernel_size=(3, 3), activation='relu', padding='same', name='block5_conv3'))model.add(MaxPooling2D(pool_size=(2, 2), strides=(2, 2), name='block5_pool'))model.add(Flatten())model.add(Dense(4096, activation='relu', name='fc1'))# model.add(Dropout(0.5))model.add(Dense(4096, activation='relu', name='fc2'))# model.add(Dropout(0.5))model.add(Dense(1000, activation='relu', name='fc3'))# model.add(Dropout(0.5))model.add(Dense(10, activation='softmax', name='prediction'))model.compile(optimizer=SGD(lr=0.05, decay=1e-5), loss='categorical_crossentropy', metrics=['accuracy'])model.summary()model.fit(x_train, y_train, batch_size=64, epochs=5, validation_split=0.16666)score = model.evaluate(x_test, y_test)print("loss:", score[0], "acc:", score[1])在训练完毕后我们还可以直接保存这个模型,调用的函数是:
model.to_json():把模型的结构写出为一个json文件model.save_weights():把模型的参数(权重)保存为一个h5文件model.load_from_json()、model.set_weights():载入网络结构和网络的参数(权重)
例如,对上文中VGG-16的模型可以采用以下脚本保存脚本:
xxxxxxxxxx# save modelwith open("./model/model_config.json", "w") as file: file.write(model.to_json())model.save_weights("./model/model_weights.h5")# model.save("./model/model_config_and_weights.h5") # 同时保存模型和训练参数# 载入方式# model = keras.models.load_model('model_config_and_weights.h5') # 同时载入# with open("./model/model_config.json", "r") as file:# json_string = json.load(file)# model = models.model_from_json(json_string)# model_weights = models.load_model('model_weights.h5')# model.set_weights(model_weights)